С наукой о данных я познакомилась в 2021 году. Мой коллега поделился проектом, в котором были файлы: синтаксис Python, визуализация данных, прогнозирование, текстовая аналитика и т.д. Я начала внедрять в дисциплины, которые вела на кафедре. Сама училась на разных курсах, получила несколько сертификатов по аналитике данных и учила новым знаниям студентов 2 курсов. Результаты были хорошими.
Идея работы с данными по КР возникла 3 года назад. Вместе со студентами мы пользовались открытыми данными КР, я серфила по сайтам, искала в таблицах, в документах, на сайте НацСтатКома. Подготавливала задания с реальными данными КР. С 2021 по 2025 гг. мои студенты показали хорошие результаты. Научились анализировать данные, находить отклонения, строить графики, прогнозировать данные. Но информация и технологии быстро устаревают. Появились чаты ИИ, курсы для желающих освоить ИТ направления. Сегодня с наукой о данных можно работать кому угодно, начиная с детского сада и пенсионеры, которые хотят освоить новые инструменты. Возможности у человека безграничны.
Инструмент, который понадобился мне в 2021 году в освоении Python, это Jupyter Notebook. В 2024 году на курсе узнала, что можно еще использовать облачное решение Jupyter Colab.
Данные, которые мы использовали в одном из заданий, это данные о землетрясениях, ощутимых на территории КР. Это будет маленький проект по анализу данных. Идея по наполнению контентом данный сайт возникла давно, но я все ждала, чтобы этот сайт содержал только технорассказы, сказки, стихи и т.д. Так как вся моя энергия и внимание направлена на студентов в ВУЗе, значит, моя деятельность должна быть описана здесь в области информационных технологий.
Итак, я установила инструмент через платформу Anaconda Navigator. Создаем файл Notebook с расширением *.ipynb (Рис. 1).
Рис.1
Нам понадобится библиотека pandas для работы с табличными данными. Для установки необходимо в строке кода написать pip install pandas. Для работы с библиотеками Python используем ключевое зарезервированное слово import. Мне понадобятся еще другая библиотека для визуализации данных -seaborn.

Рис.2
Для запуска можно использовать Ctrl+Enter или в меню кнопка Run. Данные с веб сайта seismo.kg я заранее скачала (на дату 30.08.2025).

Рис.3
Как видно на рисунке использую для чтения данных в формате CSV(Comma separated value – данные, разделенные запятыми) read_csv. Если данные у вас в формате excel, используйте функцию read_excel().
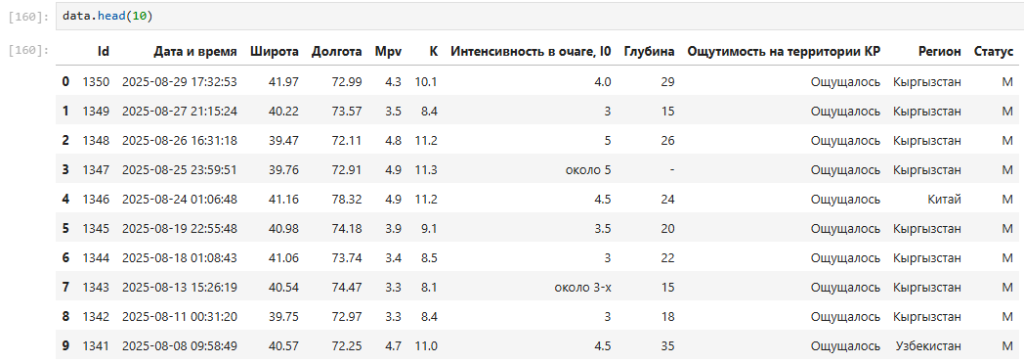
Рис.4
На рис.4 отображены первые 10 записей из файла.
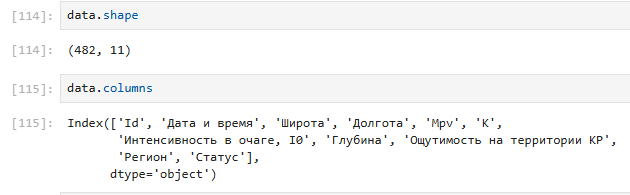
Рис.5
Функция shape() используется для просмотра количества столбцов и строк файла.
Columns отображает количество столбцов и их названия.
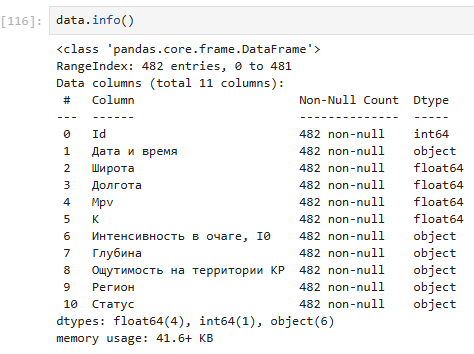
Рис.6
Функция info()- отображает информацию о файле. Файл содержит 10 столбцов и 481 строки.
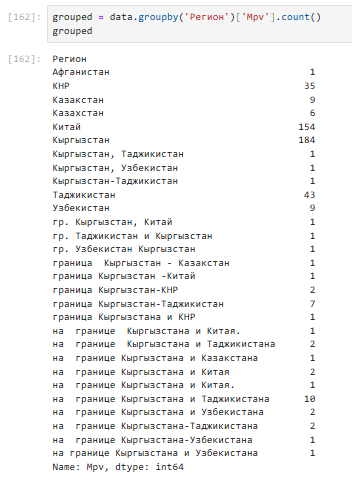
Рис.7
Функция groupby() использую для группировки данных по столбцу ‘Регион’.
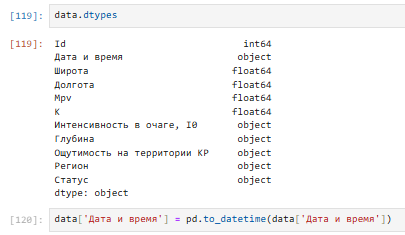
Рис.8
Функция dtypes() -используется для просмотра типов данных столбцов файла. Меня интересует столбце ‘Дата и время’, столбце надо конвертировать в формат datetime, и использую функцию to_datetime().
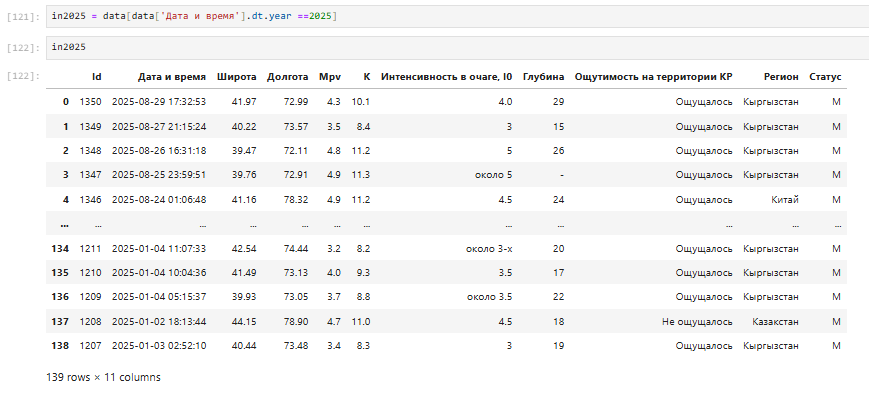
Рис. 9
С начала года по 30.08.2025 произошло 139 землетрясений. А за 2024 год произошло 384 землетрясения(рис10).
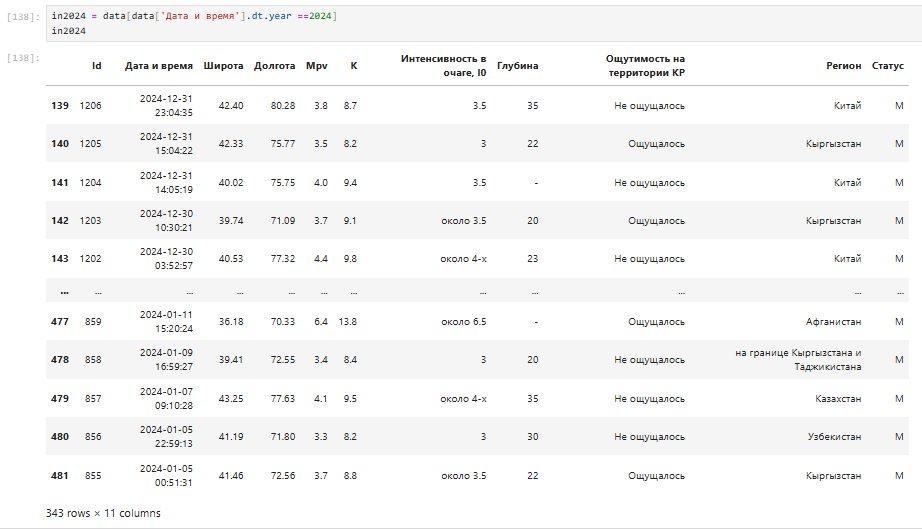
Рис.10
Далее мне интересно посмотреть на график. Для визуализации использую функцию countplot().
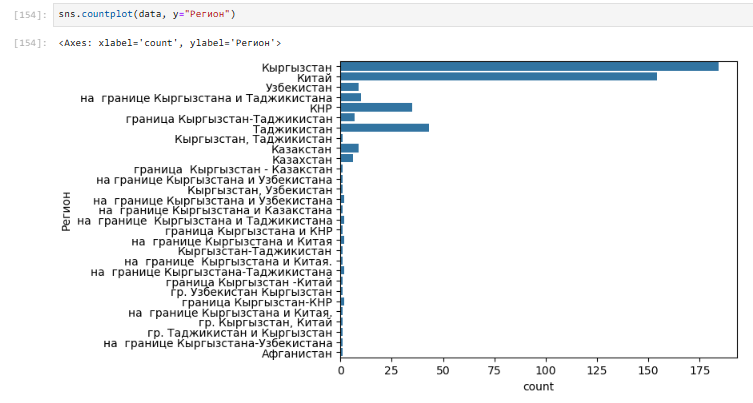
Рис.11
Построим столбчатую диаграмму, использую функцию barplot().

Рис. 12
Это был отрывок нашего задания по работе с реальными данными. В итоге, мы установили инструмент Jupyter Notebook, загрузили данные с веб сайта seismo.kg, использовали 2 библиотеки для работы с табличными данными и для визуализации данных.
30.08.2025